
Removing Barriers of Silos for Data Analysis: Building a Unified Data Platform
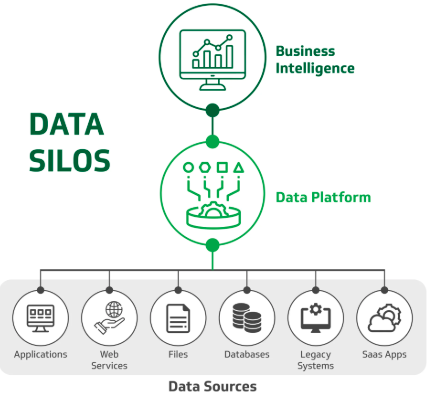
In today's data-driven world, organizations struggle with fragmented data stored across multiple silos, making it nearly impossible to gain comprehensive insights. Brainstack Technologies helped a public research institute break down these barriers by creating a unified data platform that aggregates information from years of siloed systems, reducing costs by 60% while dramatically improving data consistency and availability.
Project Overview
Client: National Research Institute for Public Health
Industry: Public Sector & Research
Challenge: Data silos causing high costs, inconsistent data availability, and inability to perform comprehensive analysis
Solution: Unified data platform with ETL pipelines, data warehouse, and real-time analytics capabilities
The Challenge
Our client, a leading public research institute, had been managing critical research data across multiple isolated systems for over a decade. Each department maintained its own database, using different formats, schemas, and storage solutions. This fragmentation created significant challenges:
- High Operational Costs: Maintaining multiple database systems, each requiring separate infrastructure, licensing, and maintenance teams
- Inconsistent Data Availability: Critical information scattered across systems, making it difficult to access when needed for research and reporting
- Data Quality Issues: Duplicate, conflicting, and outdated information across different silos, leading to unreliable analysis results
- Limited Cross-Department Analysis: Inability to correlate data from different departments, missing valuable insights that could emerge from unified datasets
- Compliance Challenges: Difficulty in maintaining data governance, audit trails, and meeting regulatory requirements across fragmented systems
- Time-Consuming Reporting: Generating comprehensive reports required manual data extraction from multiple sources, taking weeks instead of hours
"We were spending more time trying to find and consolidate data than actually analyzing it. Our researchers were frustrated, and our decision-making was based on incomplete information. We needed a solution that would break down these barriers and give us a single source of truth."
Our Solution: Unified Data Platform
Brainstack Technologies designed and implemented a comprehensive data engineering solution that unified all data sources into a single, accessible platform. Our approach focused on data integration, quality assurance, and real-time analytics capabilities.
1. Data Integration & ETL Pipelines
We developed robust Extract, Transform, and Load (ETL) pipelines that automatically aggregate data from all existing silos:
 Legacy System Integration
Legacy System Integration
Connected to 12 different legacy systems including Oracle databases, SQL Server instances, Excel files, and CSV exports. Implemented custom connectors for each system to handle unique data formats and schemas.
Real-Time Data Synchronization
Established real-time data pipelines using Apache Kafka and Apache NiFi to ensure data from source systems flows into the unified platform within minutes of updates, enabling near real-time analytics.
Data Quality & Validation
Implemented comprehensive data quality checks including duplicate detection, format standardization, missing value handling, and validation rules to ensure data integrity across all sources.
2. Centralized Data Warehouse
Built a modern data warehouse using a star schema design that organizes data into fact and dimension tables, enabling fast and efficient querying for analytical purposes. The warehouse supports:
- Historical data retention with time-based partitioning
- Scalable storage architecture handling petabytes of data
- Optimized indexing strategies for common query patterns
- Data versioning and audit trails for compliance
3. Data Lake for Raw Data Storage
Created a data lake architecture to store raw, unprocessed data from all sources in its original format. This allows researchers to access original data when needed and enables future analytics use cases without data loss.
4. Analytics & Visualization Platform
Developed a self-service analytics platform that enables researchers and analysts to:
- Query unified datasets using SQL and visual query builders
- Create interactive dashboards and reports without IT assistance
- Perform advanced analytics including statistical analysis and predictive modeling
- Export data in various formats for external analysis tools

Technical Implementation
Data Integration Stack
Core Technologies
- Apache Kafka for real-time data streaming
- Apache NiFi for data flow management
- Apache Airflow for workflow orchestration
- Python and PySpark for data processing
- SQL Server Integration Services (SSIS) for legacy integration
Storage & Analytics
- Azure Data Lake Storage for data lake
- Azure Synapse Analytics for data warehouse
- Power BI for visualization and reporting
- Apache Spark for big data processing
- Azure Data Factory for ETL orchestration
Migration Strategy
- Assessment Phase: Analyzed all data sources, identified data quality issues, and mapped data relationships
- Pilot Implementation: Started with two high-priority departments to validate the approach
- Incremental Rollout: Gradually migrated remaining departments one at a time
- Parallel Operations: Maintained legacy systems running during transition for data validation
- Training & Adoption: Provided comprehensive training to researchers and analysts on new platform
Results & Impact
Cost & Efficiency Improvements
- 60% reduction in infrastructure and maintenance costs
- 80% reduction in time to generate comprehensive reports
- 90% improvement in data availability and accessibility
- 75% reduction in data quality issues and inconsistencies
Business Benefits
- Unified view of all research data across departments
- Faster decision-making with real-time data access
- Enhanced research capabilities with cross-departmental analysis
- Improved compliance with centralized audit trails
"The unified data platform has transformed how we work. What used to take weeks of manual data gathering now takes minutes. Our researchers can focus on analysis instead of data collection, and we're discovering insights we never could have found before."
Key Features Delivered
- Single Source of Truth: All data consolidated into one accessible platform, eliminating confusion from multiple data sources
- Real-Time Data Updates: Automatic synchronization ensures data is always current and available for analysis
- Self-Service Analytics: Researchers can access and analyze data independently without waiting for IT support
- Data Governance: Centralized policies and controls ensure data quality, security, and compliance
- Scalable Architecture: Platform designed to handle growing data volumes and new data sources as the institute expands
- Historical Data Preservation: Complete audit trail and versioning maintain historical context for all data changes
Lessons Learned
This project provided valuable insights into data engineering and silo elimination:
- Thorough data assessment upfront is critical for successful integration
- Data quality issues must be addressed early in the process
- User training and change management are essential for adoption
- Incremental migration reduces risk and allows for learning and adjustment
- Real-time capabilities significantly enhance the value of unified data platforms
Future Enhancements
Based on the success of this implementation, we identified opportunities for future improvements:
- Machine learning integration for predictive analytics and automated insights
- Advanced data visualization with interactive dashboards
- API layer for programmatic data access and integration with external systems
- Data catalog for improved data discovery and documentation
- Enhanced security features including role-based access control and data encryption
Conclusion
This data engineering project demonstrated Brainstack Technologies' expertise in breaking down data silos and creating unified, accessible data platforms. By consolidating fragmented data sources into a single, well-architected platform, we enabled the research institute to reduce costs, improve data quality, and unlock valuable insights that were previously impossible to discover.
The transformation not only solved immediate technical challenges but also positioned the organization for data-driven decision-making and future growth. With a unified data platform, the institute can now leverage its data assets more effectively, enabling better research outcomes and more informed policy decisions.
Ready to Break Down Your Data Silos?
Contact Brainstack Technologies to discuss how we can help you unify your data sources, reduce costs, and unlock valuable insights from your fragmented data systems.
Newest Post



